A common question I get year after year is: “How can I find all the pages that don’t have a category text?” or “How can I scrape content with Screaming Frog?”. In other words, Search Engine Optimizers want to identify pages where the category text is missing so they can add it, along with relevant keywords, to improve rankings on Google. Or maybe they want to scrape their site to build a custom GPT.
The answer to that is using Custom Extraction in Screaming Frog combined with XPath.
Extracting Content from Your Site
When you run a basic crawl in Screaming Frog, you usually gather meta titles, descriptions, headers (H1, H2, H3), internal/external links, and other SEO-related elements—but not the actual content on the page. However, with Custom Extraction and XPath, you can do that.
By scraping for example all your category pages, you can easily filter out URLs where the category text is missing, as well as those where it’s present but needs updating.
Of course, you can extract more than just category text. Custom Extraction can be used to pull any content you want from your website, whether it’s product descriptions, category texts, or specific sections of the page – you just have to find the right part of your website that you want to scrape. You can find that in the Inspector tool. Product and category texts are particularly important in eCommerce SEO, so this technique is especially useful in that context. Annd also if you build custom GPTs, scraping content to a csv file is the way to go to train your GPT on your data.
What is XPath and how to use it for extracting content in Screaming Frog?
XPath (XML Path Language) is a query language used to locate and extract elements within an XML or HTML document. In web scraping, it’s commonly used to find specific HTML elements, such as divs, spans, or other tags, based on their attributes like class names, IDs, or structure.
While XPath was originally designed to navigate through XML documents, it’s also very useful for navigating HTML because web pages are essentially structured in a similar hierarchical way.
You don’t fully need to understand XPath in all its complexity, neither do I! But here is something I have learnt, and that is scraping product and category content as I need this often in my work. Using it, I’ve managed to extract entire websites’ content and organize it neatly into a spreadsheet.
Now, let’s go through how you can use XPath with Screaming Frog to extract content, even if you’re not an XPath expert.
Watch the step by step video or read the guide below on how I scrape product and category texts with Screaming Frog.
How to custom extract content from your site?
Step by step guide to extracting product texts from a website with custom Extraction in Screaming Frog using XPath.
1. Inspect the right element to extract.
2. Find the part on your website that you want to extract.
3. Use XPath to extract content from specific divs or spans, using their class ID. One of the following XPath usually works. Replace the “example” part with the one on your site.
//div[@class="example"]
//span[@class="example"]4. Open custom extraction in Screaming Frog.
5. Add your XPath to the custom extraction. Choose to extract text.
6. Start crawling, and scroll right to see if it worked.
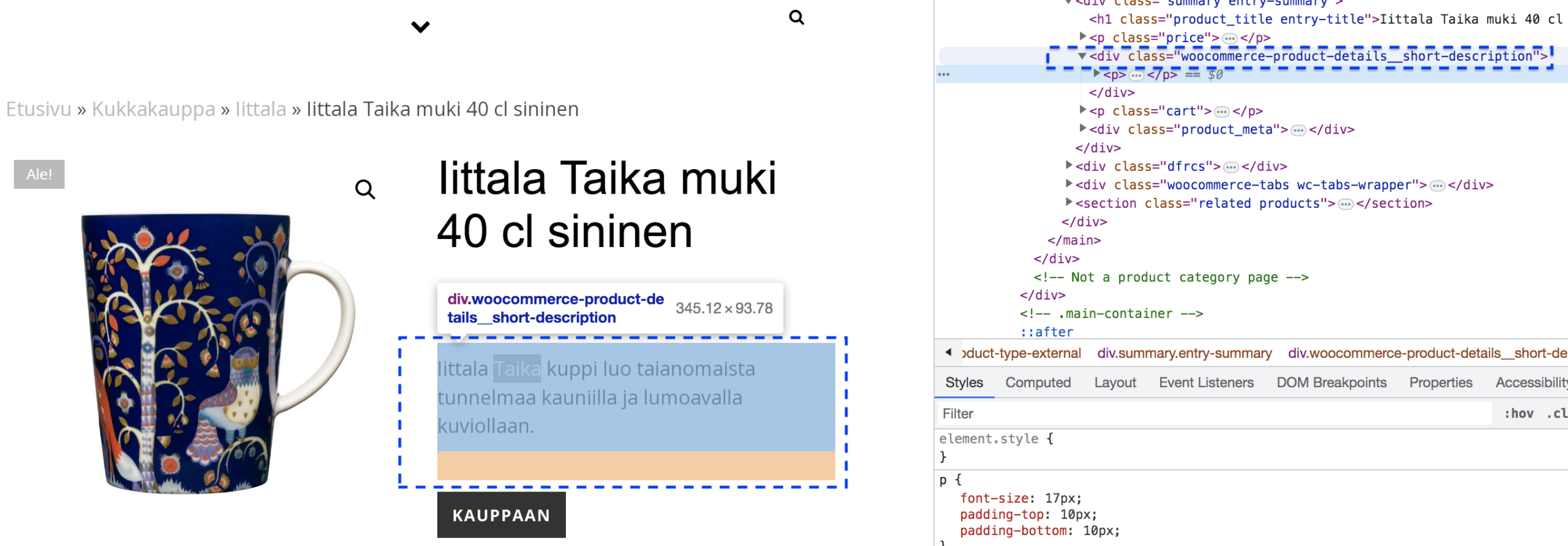
- Inspect the right element to extract
Right click and use inspect to find the part on you website that you want to extract.

- Find the part to extract.
Find the part on your website that you want to extract.
- Make the Xpath
The following XPath will extract content from specific divs or spans, using their class ID. You’ll need to replace that with your own. I use one of this almost always when extracting specific content from a website, replacing the “example” with my own data of course. Use that info and replace the “example” with the class from your site, using my cheat sheet to help you.
//div[@class=“example“]//span[@class=“example“] - Custom extraction
Open custom extraction in Screaming Frog.

- Add your XPath
Add your XPath query to the custom extraction. Choose to extract text.

- Start your crawling.
Start your crawl, and scroll right to see if it worked.

Want to learn more about Custom Extraction and Screaming Frog?
If you want to dig deeper into Web Scraping & Data Extraction Using The SEO Spider, find the Web Scraping & Custom Extraction guide by Screaming Frog.
Interested in more educational content?
Katarina Dahlin is also an educator and offers SEO-education in finnish (SEO-koulutukset), and she runs her webinar serie called SEO Case Stories, where she showcases how she optimizes her site for one year.